k-mooc의 강의를 듣고 정리한 글임을 밝힙니다.
강화학습
주어진 상황(State)에서 보상(Reward)을 최대화할 수 있는 행동(Action)에 대해 학습하는 것을 의미한다.
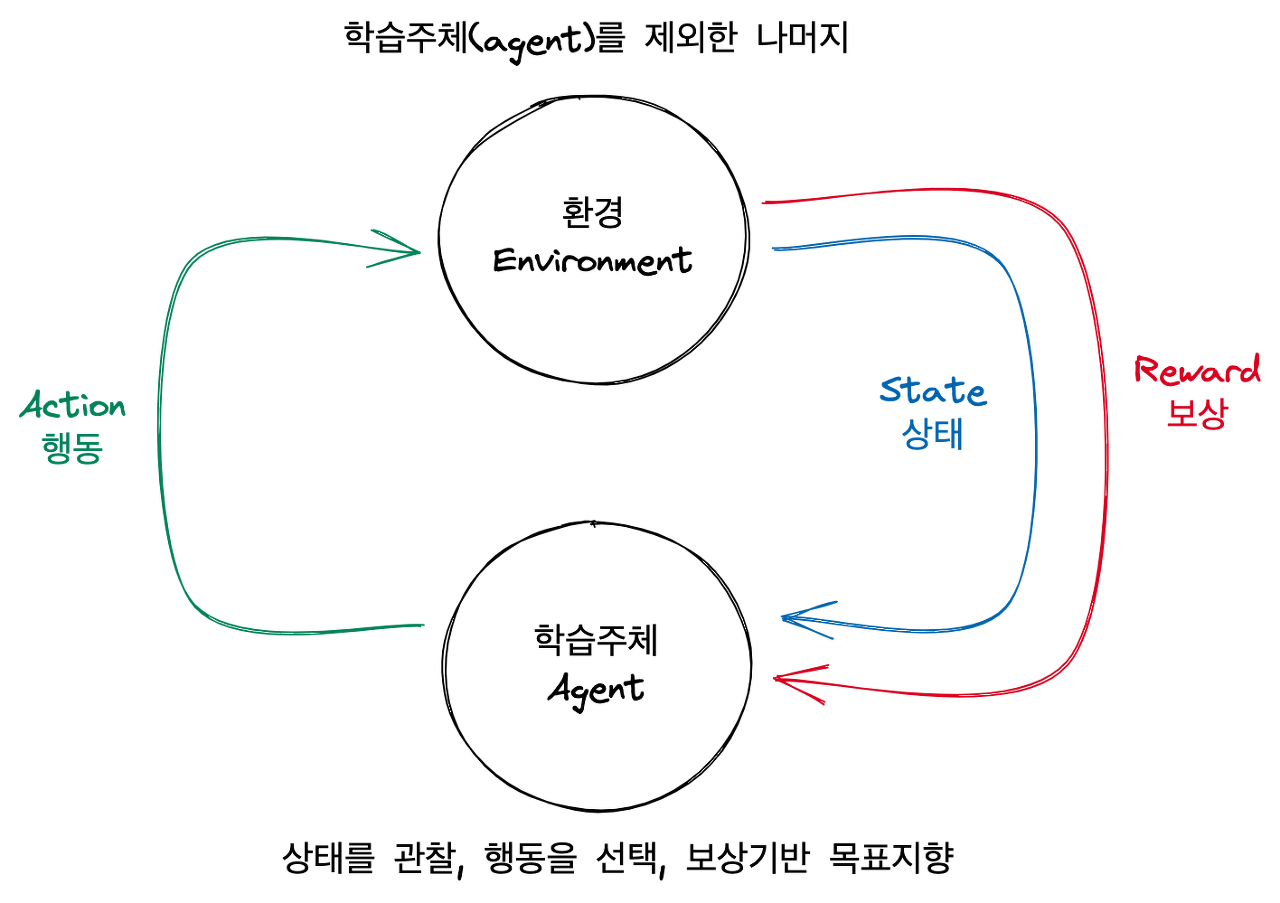
- 학습 주체(agent)는 환경(Env)에 대해 모르는 상태에서 학습
- 적합한 행동 학습을 위한 시행착오 필요 (Trial & error)
- 현재 행동이 미래 순차적 보상에 영향 (delayed reward)
- 환경과 상호작용을 통해 얻은 보상(reward)으로부터 학습
대표적 EX) 벽돌깨기 게임
- 상황 / 상태(State) : 현재 벽돌의 상태, 구슬의 위치, 하단 바의 위치 등의 정보
- 행동(Action) : 상황 정보를 가지고 하단 바를 어떻게 움직일지 결정
- 보상(Reward) : 어떤 행동을 했을 때 벽돌이 깨지는 양
ex) alphaGo, google의 데이터센터 에너지 관리, 로봇제어, AWS deep Racer 등
Multi-armed Bandit 문제 (초기 형태의 강화학습)
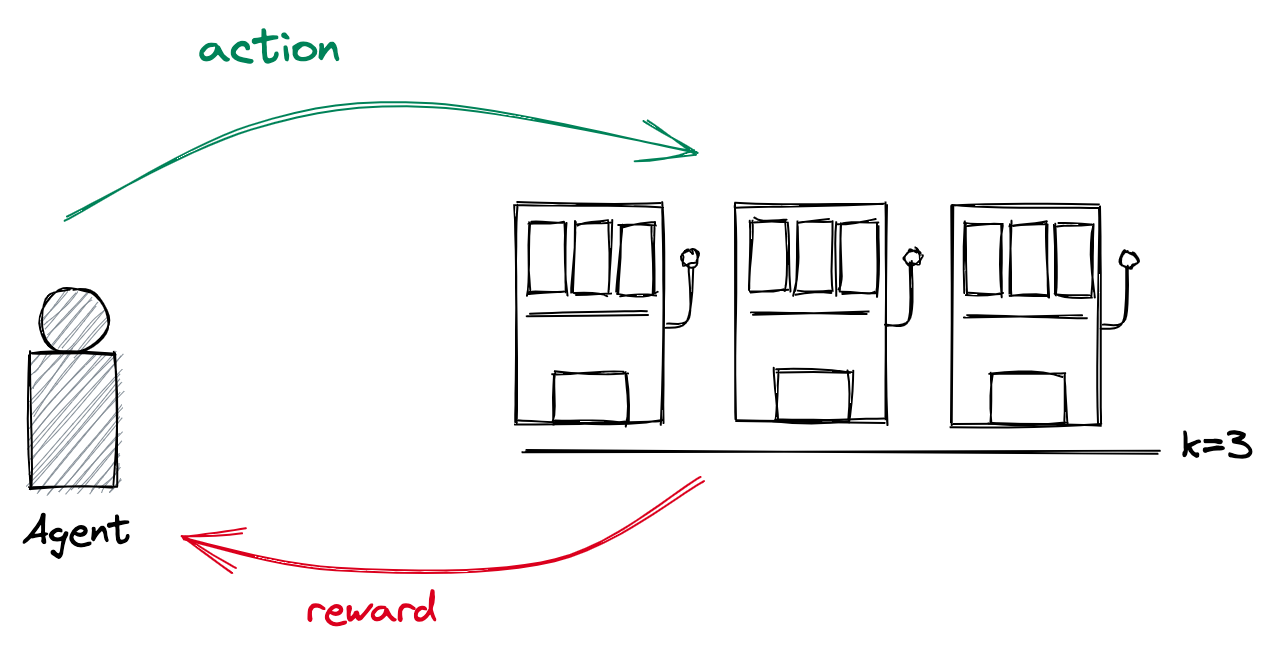
- 각 bandit machine에 대한 상태(state) 정보 부재
- 행동(action)에 대한 즉각적인 보상(reward)
< 진행 방법 >
1. 상태 정보가 없으므로 랜덤 하게 시도하여 탐색 시작 : Exploration
2. 시도를 통한 보상값을 보고 최적의 의사결정 : Exploitation
< 우리의 행동과 목적 >
주어져 있는 횟수에서 총 보상 최대화를 위한 슬롯머신 선택
- 학습 주체(agent)가 k개의 행동(action) 중 하나를 선택하고,
- 선택한 행동에 따라 보상(reward)을 받는 일련의 과정을 통해
- 일정 기간 동안 취득한 보상의 총합에 대한 기댓값을 최대화하도록
- 어떠한 행동들을 취할지 결정하는 문제
행동가치 (action values)
특정 시점에서 어떠한 행동을 취했을 때의 보상에 대한 기댓값
📌 < k-armed bandit의 문제 >
→ 어떤 보상에 대한 분포를 모르는 것
→ 최적의 행동가치에 대한 정보 부재
따라서,
반복된 실험을 통해 얻은 정보를 기반으로 행동가치를 추정
- 표본평균 방법(sample-average method)
$$ Q_t(a) = {t시점까지\ 행동 a를 \ 선택 \ 시 \ 취득한 \ 보상 \ 합 \over t시점까지 \ 행동 \ a를 \ 선택한 \ 횟수} $$
- 증분 업데이트 규칙(incermental update rule)
$$ Q_{n+1} = Q_{n} + {1\over n}*(R_{n} - Q_n) $$
- n 번 시도까지의 보상의 평균치는 현재의 보상정보와 n-1 번째 시도까지의 보상의 평균치의 차이를 업데이트하여 반영한다
- 보상값을 매번 계산하는 것이 아니라 Q값을 계속 업데이트하여 트래킹

비정상성 상황
현재까지는, 모든 단계에서 얻는 보상의 가중치가 동일하다는 가정하에 평균치를 계산
그러나,
우리가 접하는 상황들은 시간에 따라 보상의 가치가 달라질 수 있음! → Nonstationary(비정상성 상황)
이 상황에 대비하기 위해 다음과 같은 식으로 일반화를 진행!
$$ \begin{matrix} Q_{n+1} &=& Q_n + \alpha_n(R_n - Q_n) \\ &=& \alpha_nR_n + (1-\alpha_{n})Q_n \end{matrix} $$
$\alpha_n$을 이용해 임의로 업데이트 가중치 값을 조정하면 매 시점마다 유연하게 보상의 가치를 반영할 수 있다.
🧷 추정치 업데이트 방식
→ 새로운 정보와 기존 정보의 차이만큼을 반영하겠다!
$$ \begin{matrix}V &\leftarrow& V + \alpha(\hat V - V)\ \cdots \ 새로운 \ 정보와 \ 기존 \ 정보의 \ 차이를 \ 반영 \\ &\leftarrow& (1 - \alpha)V + \alpha \hat V \ \cdots \ 기존 \ 정보와 \ 새로운 \ 정보의 \ 가중평균 \end{matrix} $$
'Data Science > Reinforcement' 카테고리의 다른 글
| 강화학습의 개념 (0) | 2023.05.09 |
|---|---|
| 4.3 마르코브 보상 프로세스 : 강화학습의 수학적 기초와 알고리즘의 이해 (0) | 2022.11.07 |
| 4.1 마르코브 프로세스 개요 : 강화학습의 수학적 기초와 알고리즘의 이해 (2) | 2022.11.02 |
| 2.2 동적계획법, 중첩되는 부분문제와 역진귀납법 : 강화학습의 수학적기초와 알고리즘의 이해 (0) | 2022.11.01 |
| 2.1 문제해결전략과 동적계획법 : 강화학습의 수학적 기초와 알고리즘의 이해 (0) | 2022.11.01 |




댓글